Why OpenAI’s SynthID Move Matters for the Future of AI Image Provenance
OpenAI announced on May 19 that it is expanding how it traces AI-generated content. Images created through ChatGPT, Codex, and the OpenAI API will begin carrying Google DeepMind’s invisible SynthID watermark. At the same time, OpenAI is continuing support for C2PA Content Credentials and previewing an early verification tool that lets people upload an image and check whether it contains OpenAI provenance signals.
At first glance, this looks like a routine safety update. AI images are everywhere, so adding watermarks and verification tools seems like the obvious next step.
But one detail matters more than the feature list itself: OpenAI did not limit this to its own detection system. It chose to adopt Google’s SynthID.
That suggests something larger is happening. AI provenance is starting to move beyond a world where each company only attests to its own content. For the past two years, generated-content detection has often looked like a collection of isolated islands: one company says its model adds a marker, another platform says it can detect something, another tool says it can verify authenticity. The problem is that once an image leaves the system that made it, it enters a messy chain of social platforms, chat apps, screenshots, recompression, re-uploads, and edits. A single company’s promise rarely survives that whole journey intact.
That is why OpenAI’s decision to integrate SynthID matters. The point is not that there is now one more watermarking feature. The real point is an admission: trust in AI-generated content cannot be solved by any one vendor acting alone.
What OpenAI actually introduced
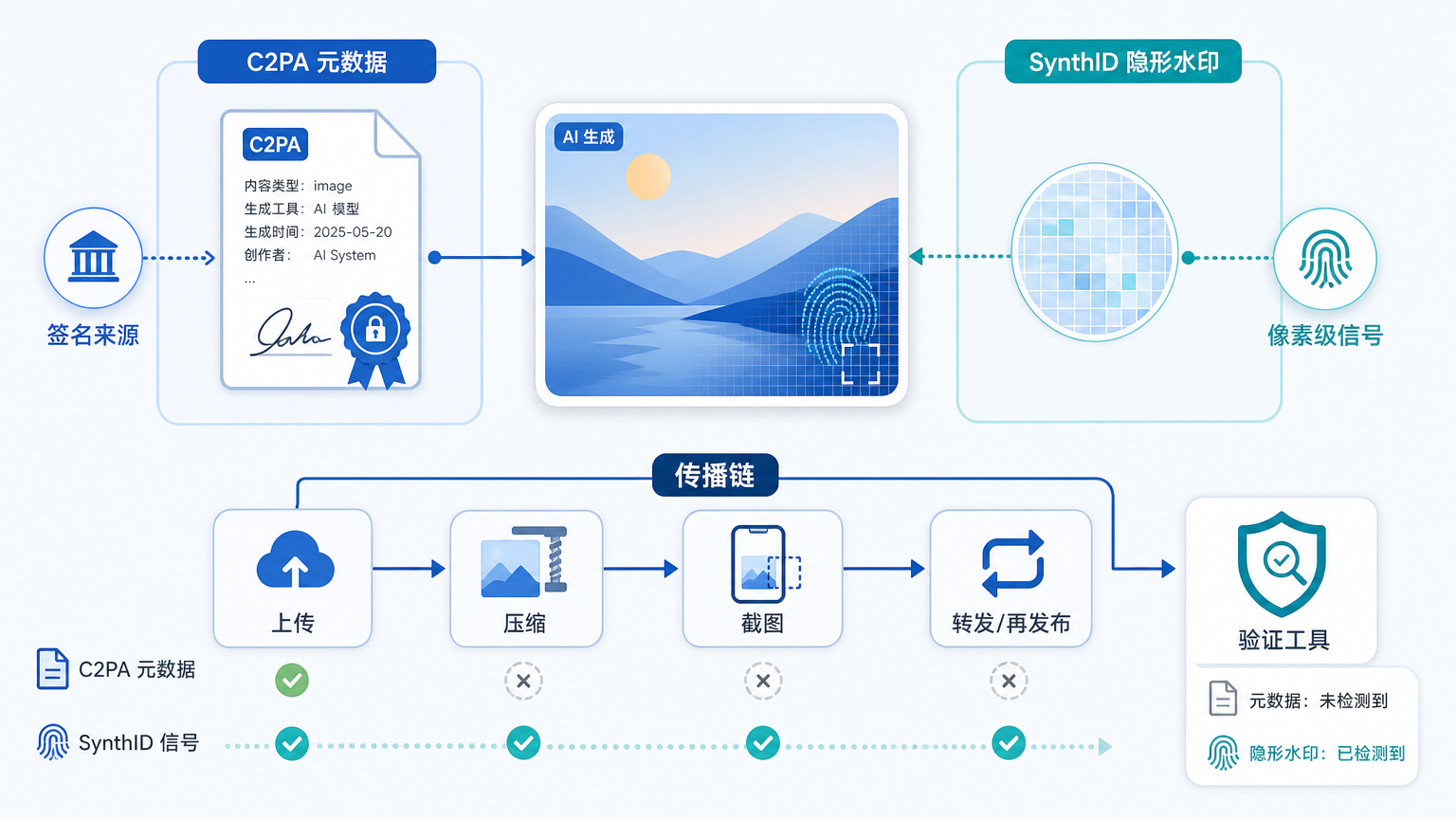
The update has three main layers.
The first is C2PA. OpenAI says it has become a C2PA Conforming Generator Product. C2PA, short for the Coalition for Content Provenance and Authenticity, is an industry standard for recording where media came from and how it was made or edited. In simple terms, it works like a signed provenance record attached to a file: where the image came from, what tools generated or edited it, and who signed that information.
That is useful for newsrooms, platforms, and ordinary users alike. It offers more than a blunt "AI-generated" label because it can preserve context rather than just attach a binary tag.
The second layer is SynthID. OpenAI will embed Google DeepMind’s invisible watermark in images. This is not a visible corner logo. It is a signal embedded into the image itself that can later be detected. OpenAI says this will begin with images generated by ChatGPT, Codex, and the OpenAI API.
The third layer is a verification tool. Users will be able to upload an image, and the tool will look for provenance signals such as Content Credentials and SynthID. If those signals are found, it can indicate whether the image appears to come from OpenAI’s generation systems.
Taken together, those three pieces are the real story: metadata provides richer context, an invisible watermark is meant to survive distribution better, and a verification tool gives ordinary users a way to inspect those signals.
Metadata is valuable, but it disappears easily
Systems like C2PA are useful, but they come with an obvious weakness: they rely on the file carrying metadata.
The real internet is not very kind to metadata. Before an image reaches someone’s screen, it may be compressed by a messaging app, re-encoded by a social platform, cropped by a content management system, exported by editing software, or turned into a screenshot and uploaded again. At any of those stages, metadata can be stripped away.
That is not a flaw unique to C2PA. It is simply how online distribution has long worked. Many platforms have never cared much about preserving image metadata, and some remove it deliberately to shrink file size or reduce privacy concerns.
So metadata alone is not enough.
That is where an invisible watermark like SynthID becomes useful. It is tied more closely to the image itself. It may not carry as much detailed information as C2PA, but it may still leave a detectable trace after screenshots, compression, or changes in dimensions.
A rough but useful analogy is this: C2PA is like a signed résumé traveling with a file, while SynthID is like a fingerprint hidden in the image texture. The résumé contains more information, but it can get lost when the file changes hands. The fingerprint contains less information, but it has a better chance of staying with the image.
OpenAI is not positioning SynthID as a replacement for C2PA. It is stacking the two together, which is a sensible direction. The distribution path for AI content is too complicated for any single technique to handle every case.
Why using Google’s watermark is more interesting than the watermark itself
OpenAI could have built only its own watermarking system and told users that images made by OpenAI could be verified with OpenAI tools.
That would still have been useful, but only inside OpenAI’s own ecosystem.
By choosing Google DeepMind’s SynthID instead, OpenAI is signaling something different. At least in image provenance, two of the most important AI camps are now showing a degree of cooperation at the infrastructure level.
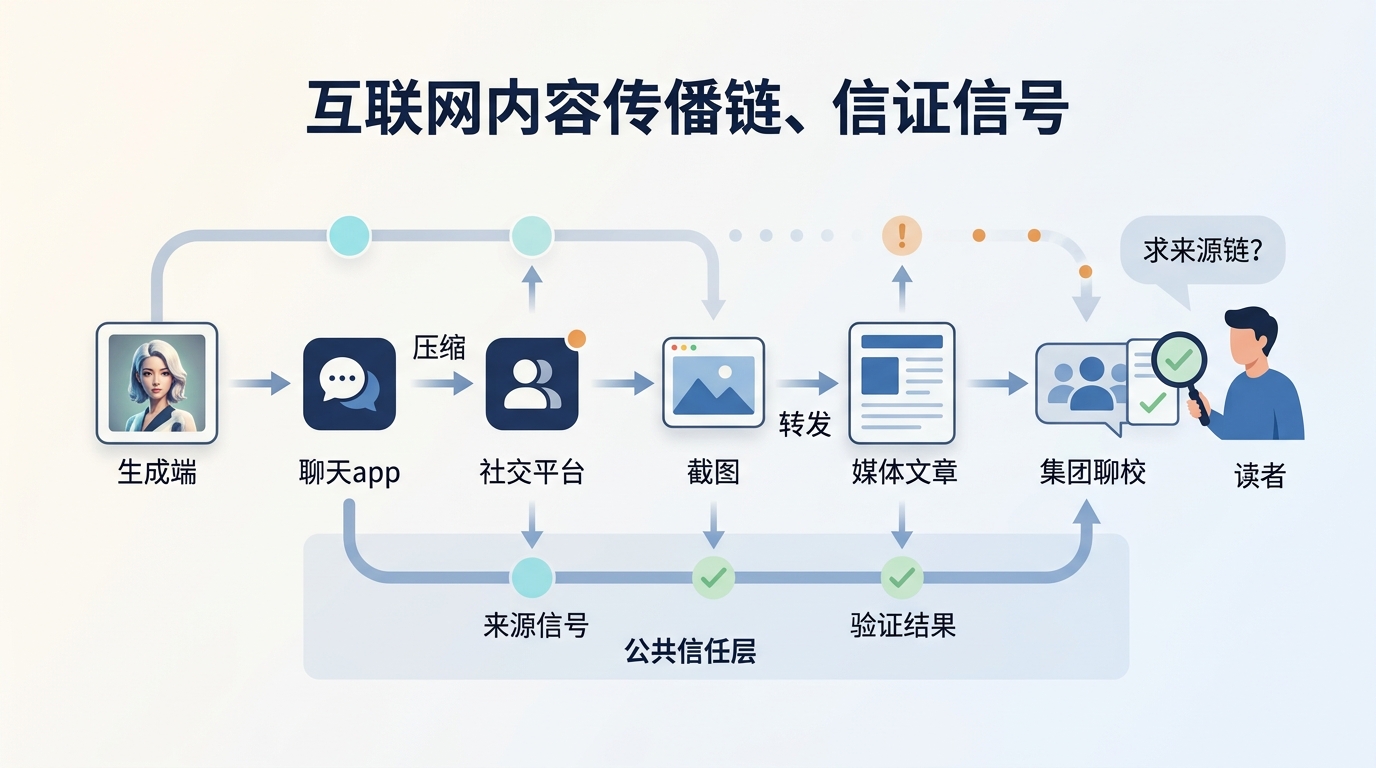
That matters more to users than it might seem. People do not usually encounter an image as a neatly labeled item inside one company’s product. They encounter it after it has already circulated. An image might be generated in ChatGPT, posted on X, reposted to another platform, quoted in a newsletter or article, and finally seen as a screenshot in a group chat. The person looking at it usually has only two practical questions: Is this AI-generated? Where did it come from?
If every company uses a completely different detection system, verification becomes clumsy. Platforms have to support many incompatible signals, and users have to remember many different tools. If content from company A requires tool A, and content from company B requires tool B, that is hard to turn into an internet-scale trust mechanism.
OpenAI’s adoption of SynthID points toward a different model: content provenance should not just be a product feature. It should act more like a shared protocol layer.
There is a familiar pattern here. Early internet trust did not scale because individual companies merely claimed they were trustworthy. It scaled when shared mechanisms such as HTTPS, email authentication, and OAuth made trust readable, transferable, and verifiable across systems.
AI provenance appears to be moving in that direction.
A verification tool is not a truth machine
OpenAI also previewed a public verification tool that can inspect uploaded images for OpenAI provenance signals, including Content Credentials and SynthID.
It is important not to misunderstand what that means.
A tool like this is not an all-purpose judge of whether an image is real or fake.
If it finds a signal, it can tell you something useful: the image likely came from OpenAI’s generation system, or at least it contains provenance markers associated with OpenAI.
If it does not find a signal, that does not prove the image was not generated by AI. The signal may have been stripped away. The image may have come from another model. It may have gone through editing or processing steps the tool cannot currently interpret. OpenAI’s own wording is cautious on this point: if metadata or a watermark is not detected, the tool does not jump to a hard conclusion.
That boundary matters. Without it, provenance tools risk being misused as another kind of magic authenticity detector.
What they can answer is: Were any origin clues found?
What they cannot answer is: Did the event depicted in the image actually happen?
An image generated by OpenAI may depict a fictional event. A photo with no watermark may still be a real photograph. Provenance verification and factual verification are not the same thing.
For media organizations, such tools can help editors evaluate where material came from. For platforms, they can become one input in moderation or review systems. For ordinary users, they can reduce some of the effort required to judge an image. But they do not replace common sense, context, or fact-checking.
The hardest part is not generation, but distribution
When people talk about AI watermarking, the discussion often narrows to a few recurring questions: Does the model add a watermark? Can users remove it? How accurate is the detector?
Those questions matter, but the biggest problem is the distribution chain.
Online content does not live as a pristine original in a filing cabinet. It travels through a pipeline of copying, compression, cropping, screenshots, and transcoding. After several rounds of circulation, the original file may no longer exist. What you see could be a screenshot of a screenshot, or a platform-reencoded version far removed from the source.
If provenance is going to be genuinely useful, it cannot depend only on OpenAI and Google doing work at the point of generation. Social platforms, media systems, image libraries, browsers, operating systems, camera makers, and editing tools all have a role to play. At minimum, they need to avoid casually wiping provenance signals away. Better still, they should be able to read those signals and present them in ways users can understand.
That is one reason open standards like C2PA matter. The goal is to let different tools interpret the same kind of provenance information instead of forcing every company to invent a private format. SynthID points in a similar direction: if more models and platforms support a detectable invisible signal, verification tools no longer have to serve only one vendor.
None of this will happen overnight. Content provenance looks less like a single product launch and more like an infrastructure migration. Standards have to converge, platforms have to integrate them, tools have to support them, and users have to learn how to interpret the results.
In the near term, this will not eliminate fake images. A more realistic goal is to make content with trustworthy provenance signals easier to identify, while requiring more supporting evidence from content that lacks such signals in high-risk contexts.
What this changes for creators
If you only use ChatGPT occasionally to make a few illustrations, this update may feel distant. But over time it could change the relationship between creators and platforms.
Until now, arguments about AI images have focused heavily on copyright, style imitation, and whether AI use should be disclosed. Another question is becoming more common: can the origin of this image be demonstrated?
For ordinary creators, provenance signals can sometimes be protective. If you generate an illustration with AI and use it openly for a stated purpose, then someone later reposts it, crops it, or republishes it in another context, provenance information can help show that the image came from a generative workflow rather than from a supposedly documentary scene.
For media organizations and brands, provenance signals are likely to become part of internal risk controls. Advertising visuals, news illustrations, and product imagery become easier to review if they carry verifiable origin information. On the other hand, in high-risk fields such as news, finance, or public safety, images without origin signals may increasingly need extra supporting proof.
Platforms face an even harder task. They cannot stop at asking whether content violates policy. They also have to deal with whether provenance signals are present, whether those signals are trustworthy, and what to do when signals are missing. That is much more complicated than slapping a generic AI label on an image.
Ordinary users also need to adjust their expectations. A watermark is not a truth label. It is an origin clue. Seeing "generated by OpenAI" does not mean the event shown is real. Failing to see a watermark does not mean the image must be authentic.
A public trust layer can also become a layer of platform power
Content provenance sounds obviously beneficial, but every trust infrastructure introduces questions about power.
If major platforms eventually require content to carry verifiable provenance, who gets to define what counts as a trusted source? If smaller tools, smaller models, or open-source models are not integrated into those standards, will their content be treated as inherently less credible? If verification tools are mainly provided by large model companies, will users be pushed into accepting those companies’ interpretation of origin?
These issues are not solved simply by invoking the phrase "open standard."
C2PA at least provides a framework for cross-industry coordination instead of leaving each company to build an opaque rule set. But open standards do not automatically produce fairness. The cost of integration, the transparency of verification, the ability of open-source communities to participate, and whether platforms are willing to preserve and display signals will all shape the outcome.
OpenAI’s use of SynthID is a positive sign because it shows major competitors are willing to share some underlying capability around content origin. But the next questions matter even more: Will other model providers join? Will social platforms display these signals? Will browsers and operating systems support them natively? Will open-source models have a low-cost way to participate?
If those questions are not addressed, provenance could turn into a mutual-recognition club among large companies rather than a broadly useful public trust layer.
The trust stack may end up with three layers
It is useful to think of AI content trust as three separate layers.
The bottom layer is marking at generation. Models or applications write C2PA, SynthID, or other provenance signals into content at the moment it is created. That answers the question of where origin information begins.
The middle layer is preservation during distribution. Social platforms, CMS tools, editing software, and browsers try to preserve, read, and pass along those signals. That answers whether origin information can survive the trip.
The top layer is interpretation for users. Verification tools, platform labels, and browser interfaces translate complex provenance signals into something understandable: what was detected, what was not detected, what the result suggests, and what it does not prove.
With this update, OpenAI is mostly working on the bottom and top layers. It is generating signals and offering a verification tool. The middle layer still depends on the broader ecosystem.
That is why this news should not be reduced to "OpenAI adds watermarks to images." A better description is that AI provenance systems are beginning to connect across company boundaries.
OpenAI’s adoption of Google’s SynthID will not make AI fakes disappear overnight, and it does not mean every AI image will be reliably identified from now on.
Its significance is more basic than that. AI companies are starting to acknowledge that content origin cannot rest on a model of "I made it, so I alone can certify it." As generated content becomes cheaper, more realistic, and more widespread, the internet needs provenance mechanisms that different systems can read, carry, and verify.
The future question for any image will not just be whether it looks convincing. Increasingly, it will also be whether it comes with a verifiable chain of origin.
That chain is not the same thing as truth. But it may become one of the starting points for rebuilding trust.