What Ollama Is and Why It Matters for Running LLMs Locally
Ollama is best understood as an open-source framework built to make large language models practical on local machines. If you have ever looked at running an LLM outside of a cloud API and felt blocked by setup complexity, hardware limits, or privacy concerns, that is exactly the gap Ollama is trying to close.
Where Ollama comes from
As the AI wave accelerated, models such as Llama and GPT showed just how capable large language models could be. But the usual way of using them—through cloud-hosted services—also exposed some very obvious trade-offs.
One problem is dependency on vendor APIs. In the cloud model, users send data out for processing, which raises privacy concerns and can create real risk around sensitive information. It also comes with ongoing usage costs that are not always easy to control. For people and organizations that care about keeping data local and keeping expenses predictable, that approach is often not ideal. Ollama emerged in response to that demand, offering a way to run LLMs locally with more control over both privacy and cost.
Another problem is deployment difficulty. Early open-source LLMs were often hard to get running unless you were comfortable manually configuring environments, resolving dependencies, and tuning inference settings. For many non-specialist users, the barrier was simply too high. Ollama tackled this by packaging model weights, inference code, and fine-tuning support in a way that enables a much simpler, almost one-command workflow. Instead of wrestling with setup details, users can start a model directly.
Its development has also been shaped by open-source and community participation. With ideas aligned to container-style packaging, Ollama organizes models into standardized modules through the Modelfile approach. That modular design makes cross-platform deployment easier, and the open-source nature of the project has helped attract contributors from different technical backgrounds. As a result, the framework has continued to improve through active iteration and community input.
Why people choose Ollama to run large models
Easier deployment from the start
The biggest reason many people try Ollama first is that it dramatically reduces setup friction.
- Ready to use: Ollama lets users download and run a model with a single command:
ollama run <模型名>. For example, enteringollama run llama2triggers the download and launch process automatically, without requiring the user to manually deal with dependencies or environment setup. - Prebuilt model library: It provides access to mainstream models such as Llama, Mistral, and Qwen, covering parameter sizes from 3B to 70B+. That range makes it useful both for lightweight local experimentation and for more demanding workloads.
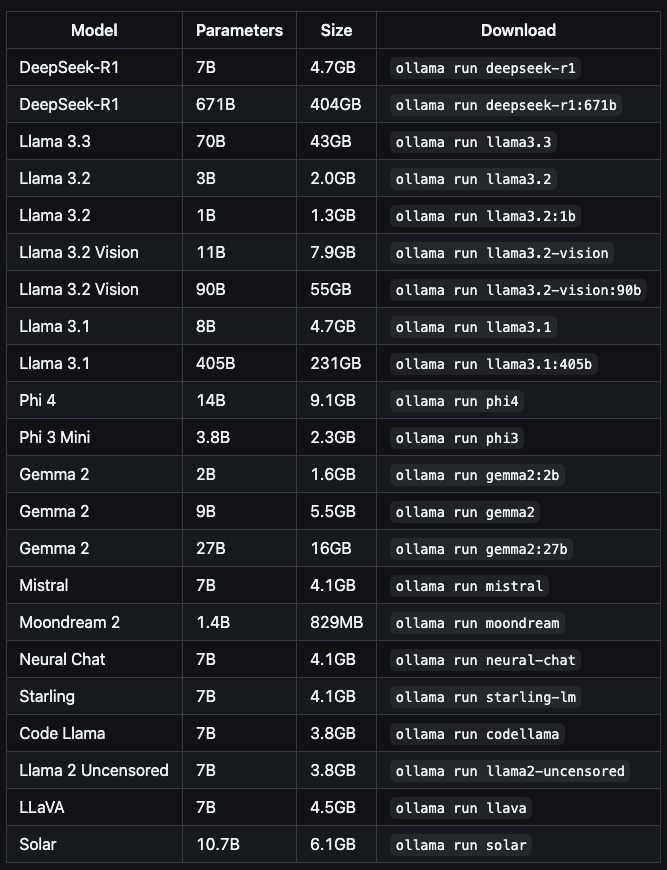
- Cross-platform support: Ollama supports macOS, with special optimization for Apple Silicon, as well as Linux, Windows in preview, and Docker-based deployment. That flexibility makes it workable on personal machines and in larger server environments alike.
Better use of limited hardware
Running LLMs locally always comes down to one question: can your hardware handle it? Ollama puts a lot of focus on making the answer more often yes.
- Weight quantization: It supports low-precision quantization methods such as INT8 and INT4. With quantization, memory usage can drop to about one quarter of the original model footprint. That makes it possible to run very large models—even 65B-scale models—on consumer hardware like a Mac with 16GB of memory.
- Chunked loading and caching: Rather than loading everything at once and exhausting memory, Ollama can process long text in chunks. It also caches previously computed context, so repeated use of historical context does not always require recomputation. This improves long-context efficiency and reduces wasted resources.
- Flexible GPU/CPU scheduling: Ollama supports acceleration on NVIDIA and AMD GPUs, which can substantially improve inference speed. At the same time, it is not limited to GPU environments. It can also run in CPU mode, with optimization through technologies such as Metal on Apple Silicon and distributed inference strategies where applicable.
Privacy and security by design
For a lot of users, local deployment is not just about convenience—it is about control.
- Fully offline operation: Ollama can run completely offline, so user data does not need to be uploaded for cloud processing. In privacy-sensitive fields such as healthcare and finance, where data can include personal information or business secrets, this local-only model is a major advantage.
- Private deployment for enterprises: Organizations can deploy Ollama in a private environment and combine it with local knowledge bases, including setups like FastGPT, to build internal AI applications. This reduces exposure of sensitive information while allowing the system to be adapted to business-specific needs.
More room for customization
Ollama is not limited to running stock models exactly as-is. It also gives users ways to adapt models to their own tasks.
- Fine-tuning support: It integrates techniques such as LoRA and Prefix Tuning. With relatively small amounts of data, users can fine-tune models for vertical domains like law or medicine, improving domain performance without the full cost of retraining.
- Importing custom models: Ollama supports importing private models from formats such as GGUF, PyTorch, and Safetensors. Users can also adjust inference behavior and performance through Modelfile-based customization.
- API compatibility: It provides an OpenAI-like REST API, which makes it easier to connect with existing toolchains such as LangChain and AutoGPT. That compatibility lowers migration cost and lets developers build on familiar workflows.
Integration with a broader tool ecosystem
Another reason Ollama has gained traction is that it does not sit in isolation.
- Visual interfaces: It works with tools such as Open WebUI and Chatbox, which provide a ChatGPT-style graphical interface. That matters for users who want a friendlier interaction layer instead of relying only on the command line.
- Distributed and concurrent processing: In high-concurrency scenarios, Ollama supports multi-GPU parallel inference and asynchronous request handling. These capabilities help improve throughput and responsiveness when many requests are being processed at once.
The core value of Ollama
Ollama stands out because it combines three things that local LLM deployment has historically struggled to deliver at the same time: simple setup, strong privacy, and efficient use of hardware.
Its minimal deployment model lowers the technical threshold so more people can run large language models locally without deep infrastructure knowledge. That has obvious value for developers, but it also opens the door for companies and individual users who previously would have stopped at the setup stage.
Its offline-first and private deployment capabilities make it especially relevant wherever data sensitivity matters. Instead of sending information outward, users can keep processing local and maintain tighter control over what happens to their data.
Its resource optimization strategy is equally important. Quantization, chunked loading, caching, and flexible CPU/GPU scheduling make large models usable on more modest hardware and improve overall efficiency.
The project’s open-source nature and active community are also part of its long-term strength. Open development brings in new contributors, new ideas, and faster iteration. A healthy community gives users a place to exchange experience, troubleshoot problems, and push the ecosystem forward together.
In practical terms, Ollama helps make large-model technology more accessible. It gives developers, businesses, and individual users a lower-cost way to explore what AI can do, without being forced into a cloud-only workflow.