Fresns Nears Its 2.0 Release With a Rebuilt Architecture for Open-Source Communities
A year has passed since Fresns last resurfaced, and this time the project is finally approaching an official release.
Pushing an open-source project forward from a product manager’s perspective has proven far more difficult than it might appear. Every idea depends on finding someone to build it, and that means searching for the right people, communicating requirements, working through differences, and reviewing the results. When any part of that process falls short, both time and money are wasted. In the end, that pressure led to a practical decision: to step in and write the code personally.
Based on the version completed a year earlier, Fresns has now gone through a major refactor. Much more attention was placed on code standards and internal consistency, which is why the first version intended for real commercial use is being positioned directly as 2.0 rather than a simple incremental update.
How Fresns is structured
The product architecture is built around the idea behind the formula algorithm + data structure = program. Following that line of thinking, Fresns was designed as a system where user interactions act on content, producing results. Those results can then be archived through different classification methods. Algorithms process those archived outcomes under specific conditions, and client applications finally interpret and render them into interfaces that users can browse and interact with again.
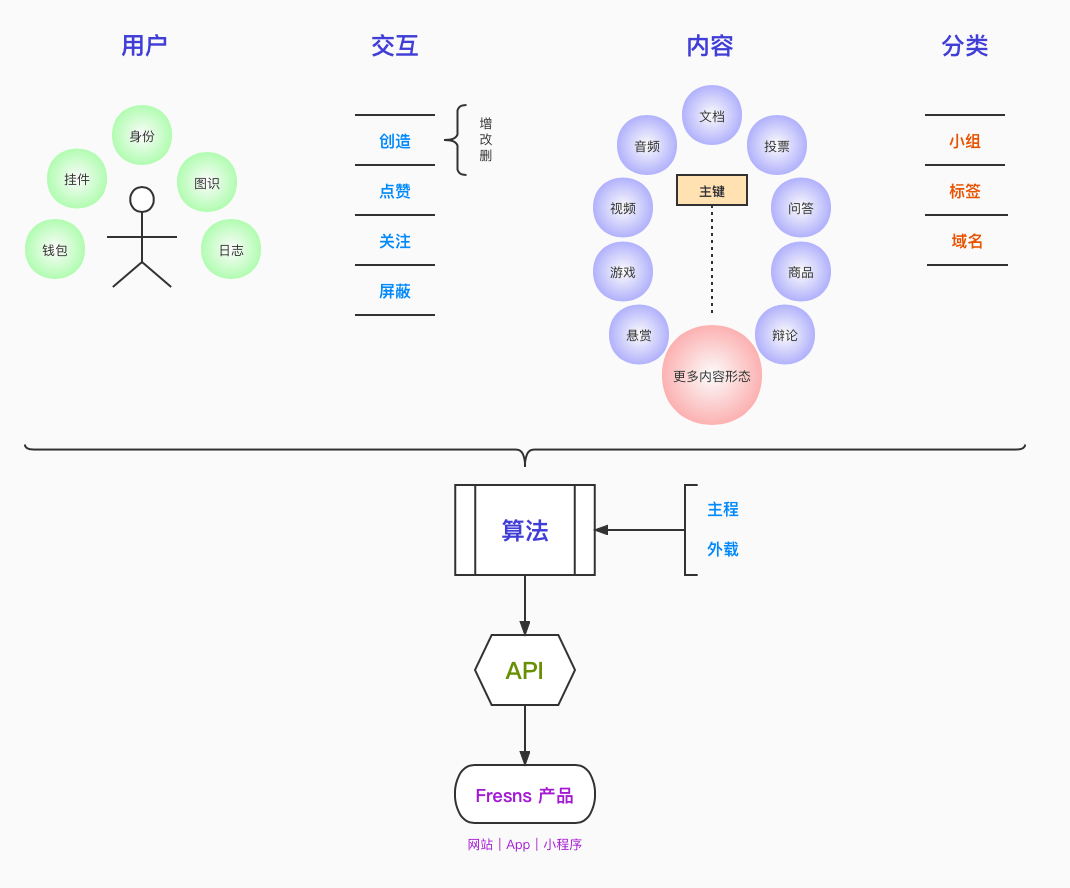
At the center of this design is data. Users, interactions, content, and categories each have their own primary keys, with additional related structures extending outward from them. The main emphasis is on defining the data model and the API layer clearly, while other feature modules are left to extension plugins.
Because of that, the plugin mechanism is embedded directly into the flow of data through the system. That approach is meant to keep usage unified and standardized across platforms while also supporting real-time behavior in a consistent way.
The core program is designed more like a scaffold or framework than a feature-heavy application. It provides only the essential API capabilities a community product cannot do without, while additional functionality is delegated to plugins. Each plugin is treated as an independent functional module. In terms of both system design and business logic packaging, communication is based on command words: a plugin module contains multiple command words, and external components invoke plugin capabilities through those commands.
For developers, this keeps the form straightforward and lowers the barrier to plugin development. For system communication, it also stays simple, since plugin calls can be handled in a way similar to RPC. From a long-term architectural perspective, this design allows a monolithic framework to support many plugins, while also creating room for a future in which multiple systems and multiple plugins can work together. It is also intended to support distributed calls between systems in a microservices-style model.
Why the model layer took so long
The model structure became the most time-consuming part of this phase. Since Fresns is an open-source product, the goal was not only to make participation easier for developers, but also to make operation more stable for the people using it. After careful consideration, the decision was made to rebuild the model structure and code conventions rather than continue layering changes onto the older design.
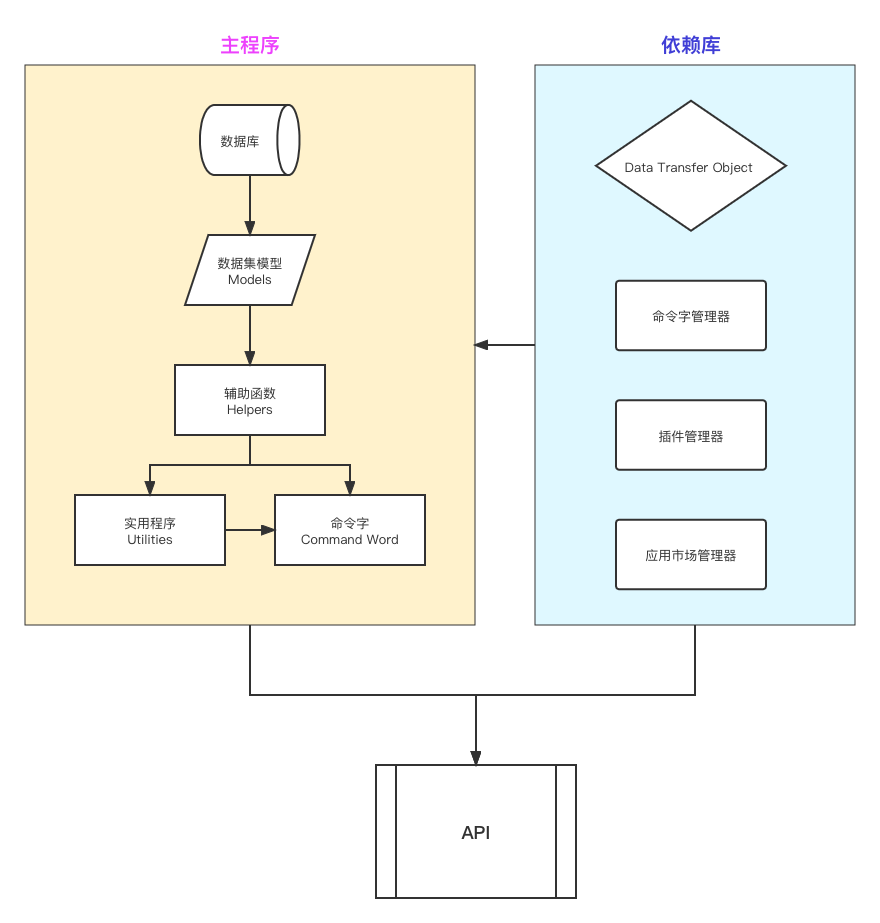
After the reorganization, the main program is much friendlier for plugin developers. The major datasets have already been encapsulated as Models. Common supporting functions are packaged as Helpers. Frequently used business features are grouped into Utilities. And business functions that need to work across domains and languages are abstracted into Command Word commands, which are also intended to serve as the foundation for future RPC capabilities.
These packaged layers are documented in detail, allowing plugin developers to call them directly and reduce duplicated development work.
For client developers, the API has also been rebuilt to fully follow RESTful standards. The result is a structure that is clearer, more standard-compliant, easier to understand, and more convenient to extend.